全国の人流オープンデータを触る(その2)
前回は「全国の人流オープンデータ」を読み込んでグラフ化をしてみました。今回は任意の箇所の人流を集計してみました。前回よりステップアップしたところは、GISのオーバーレイを使用し人口の集計を面積按分により算出すること、グラフ化はExcelではなくMatplotlibを使用してみました。
▼前回の記事です

今回の調査箇所
観光地でGISデータの入手のしやすさを考慮し、今回は世界遺産としました。まずは日光の社寺周辺で分析してみます。国土数値情報からデータをダウンロードします。地物情報のうち、構成資産範囲ポリゴンを使用します。(世界遺産には「緩衝地帯」というもう少し広い範囲のものがあるのですが、今回は構成資産の方を利用しました。)
前回同様にG空間情報センターから栃木県の人流データをダウンロードします。1kmメッシュデータは人流データの箇所にある全国のものや、国勢調査などのe-Statにもありますが、G空間情報センターに都道府県別のもの(ネオプランニングラボ株式会社)が公開されていますので、こちらから栃木県のみをダウンロードします。
QGISで読み込んで確認してみます。
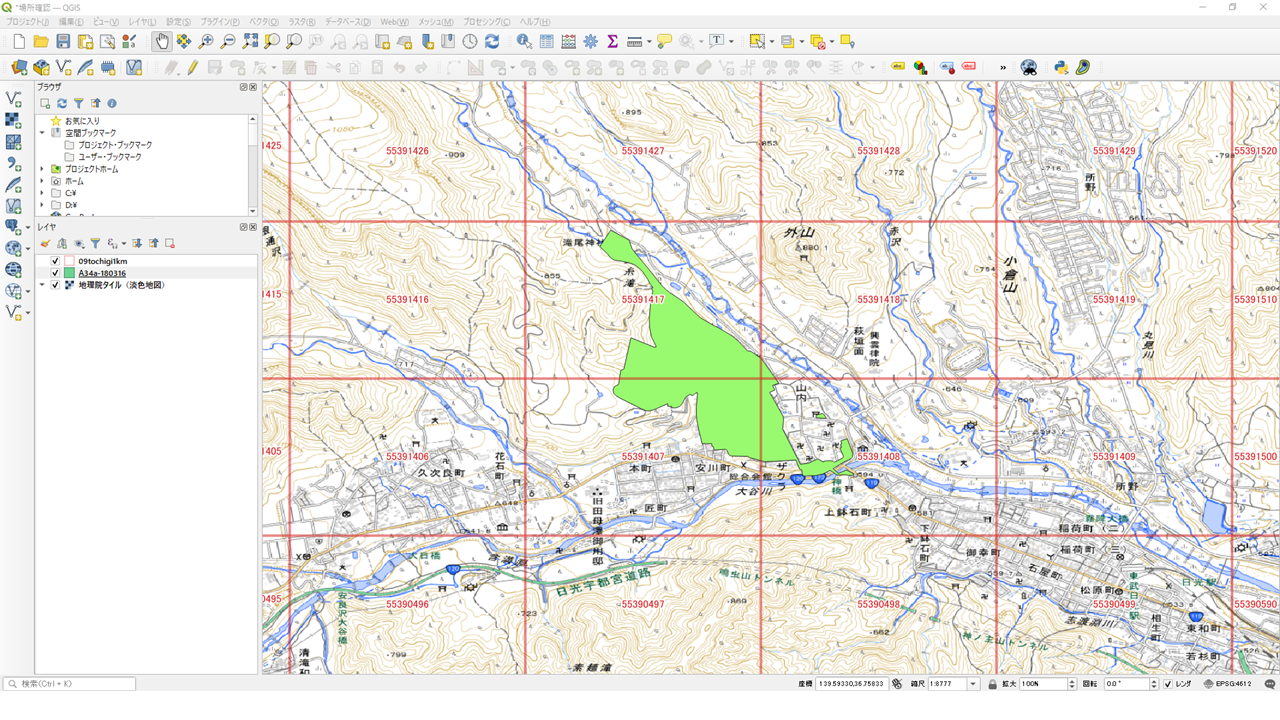
日光の社寺のポリゴンは4箇所のメッシュと重なっています。4箇所のメッシュ人口をそれぞれ按分したものを集計することになります。
人流データの読み込みと集計
Pythonを使用して前回とほぼ同様の方法で人口を集計します。まずは①世界遺産のシェープファイル、②1kmメッシュ、③人口データを保存します。
import geopandas as gpd
import pandas as pd
import zipfile
# CRSのセット
crs = 'EPSG:6677'
# 世界遺産のデータを読み込み
gdf1 = gpd.read_file('shp/A34a-180316.geojson')
# 日光を抽出
heritage = gdf1[gdf1['A34a_003']=='日光の社寺']
heritage = heritage.to_crs(crs) # 座標系の変換
heritage.to_file('output/heritage.shp', encoding='cp932') # 日光のシェープ保存
# 栃木県の1kmメッシュデータを読み込み
gdf2 = gpd.read_file('shp/09tochigi1km.geojson')
gdf2 = gdf2.to_crs(crs) # 座標系の変換
# 日光の社寺付近にかかるメッシュ番号を抽出
mesh_list = []
for index1, h in heritage.iterrows():
for index2, m in gdf2.iterrows():
if m['geometry'].intersects(h['geometry']):
mesh_list.append(m[0])
# メッシュデータの抽出
mesh = gdf2[gdf2['code'].isin(mesh_list)]
mesh.to_file('output/mesh.shp', encoding='cp932') # メッシュ4カ所のシェープ保存
# 人流データの読み込みと結合
pieces = []
file = 'pop/monthly_mdp_mesh1km_09.zip'
with zipfile.ZipFile(file) as f:
pref = f.namelist()[0]
for y in range(2019, 2022):
for m in range(1, 13):
with f.open('{}{}/{}/monthly_mdp_mesh1km.csv.zip'.format(pref, str(y), str(m).zfill(2))) as ff:
with zipfile.ZipFile(ff).open('monthly_mdp_mesh1km.csv') as fff:
frame = pd.read_csv(fff)
frame['code'] = frame['mesh1kmid'].astype(str) # 人流データはコードがint型なので
frame = frame[frame['code'].isin(mesh_list)]
pieces.append(frame)
pop = pd.concat(pieces, ignore_index=None)
pop = pop.drop(['mesh1kmid', 'prefcode', 'citycode'], axis=1)
pop.to_csv('output/pop.csv', encoding='cp932', index=None) # 人流データcsv保存

集計とグラフ作成
一旦保存したCSVファイルを読み込んで、単純にメッシュのみの人口と面積按分による人口のグラフを作成します。Matplotlibとseabornの操作は以下の書籍を参考にしました。日本語の表示については以下のYouTubeを参考にしました。
▼面積按分による人口集計はこちらの記事でもやっています

素人なので効率的なコードとは言えませんが、まずはチャレンジということで。
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 人口データ読み込み
pop = pd.read_csv('output/pop.csv', dtype={'code': 'str'})
# <単純に4カ所のメッシュのみで集計>
# グラフの準備
pop1 = pop.groupby(['year', 'month', 'dayflag', 'timezone']).sum().reset_index()
print(pop1['population'].max()) # グラフの目盛りの目安に
order = {1:[1, 0, '平日 昼間'], 2: [1, 1, '平日 深夜'], 3: [0, 0, '休日 昼間'], 4: [0, 1, '休日 深夜']} # グラフの配置と集計フラグを整理
h = 12000 # 目盛り
# グラフ作成
sns.set(font='Hiragino Maru Gothic ProN')
fig = plt.figure(figsize=(20,10))
plt.subplots_adjust(wspace=0.2, hspace=0.3)
for k, v in order.items():
df = pop1[(pop1['dayflag']==v[0]) & (pop1['timezone']==v[1])]
ax = fig.add_subplot(2, 2, k)
sns.barplot(data=df, x='month', y='population', hue='year', ci=None)
plt.ylim(0, h)
plt.title(v[2])
fig.savefig('output/graph1.png')
# <面積按分による集計>
# 世界遺産(日光の社寺)のシェープファイルを読み込み
heritage = gpd.read_file('output/heritage.shp', encoding='cp932')
# メッシュのシェープファイルを読み込み
mesh = gpd.read_file('output/mesh.shp', encoding='cp932')
mesh['area_all'] = mesh.area # 面積を算出(分母)
# オーバーレイ
over = gpd.overlay(mesh, heritage, how='intersection')
over['area_cut'] = over.area # 面積を算出(分子)
over['rate'] = over['area_cut'] / over['area_all'] # 比率
# 人口に比率をかけ、按分人口を算出
pop2 = pd.merge(pop, over[['code', 'rate']], on='code')
pop2['population'] = pop2['population'] * pop2['rate']
# グラフの準備
pop2 = pop2.groupby(['year', 'month', 'dayflag', 'timezone']).sum().reset_index()
print(pop2['population'].max()) # グラフの目盛りの目安に
h = 1500 # 目盛り
# グラフ作成
fig = plt.figure(figsize=(20,10))
plt.subplots_adjust(wspace=0.2, hspace=0.3)
for k, v in order.items():
df = pop2[(pop2['dayflag']==v[0]) & (pop2['timezone']==v[1])]
ax = fig.add_subplot(2, 2, k)
sns.barplot(data=df, x='month', y='population', hue='year', ci=None)
plt.ylim(0, h)
plt.title(v[2])
fig.savefig('output/graph2.png')では、グラフを見てみましょう。
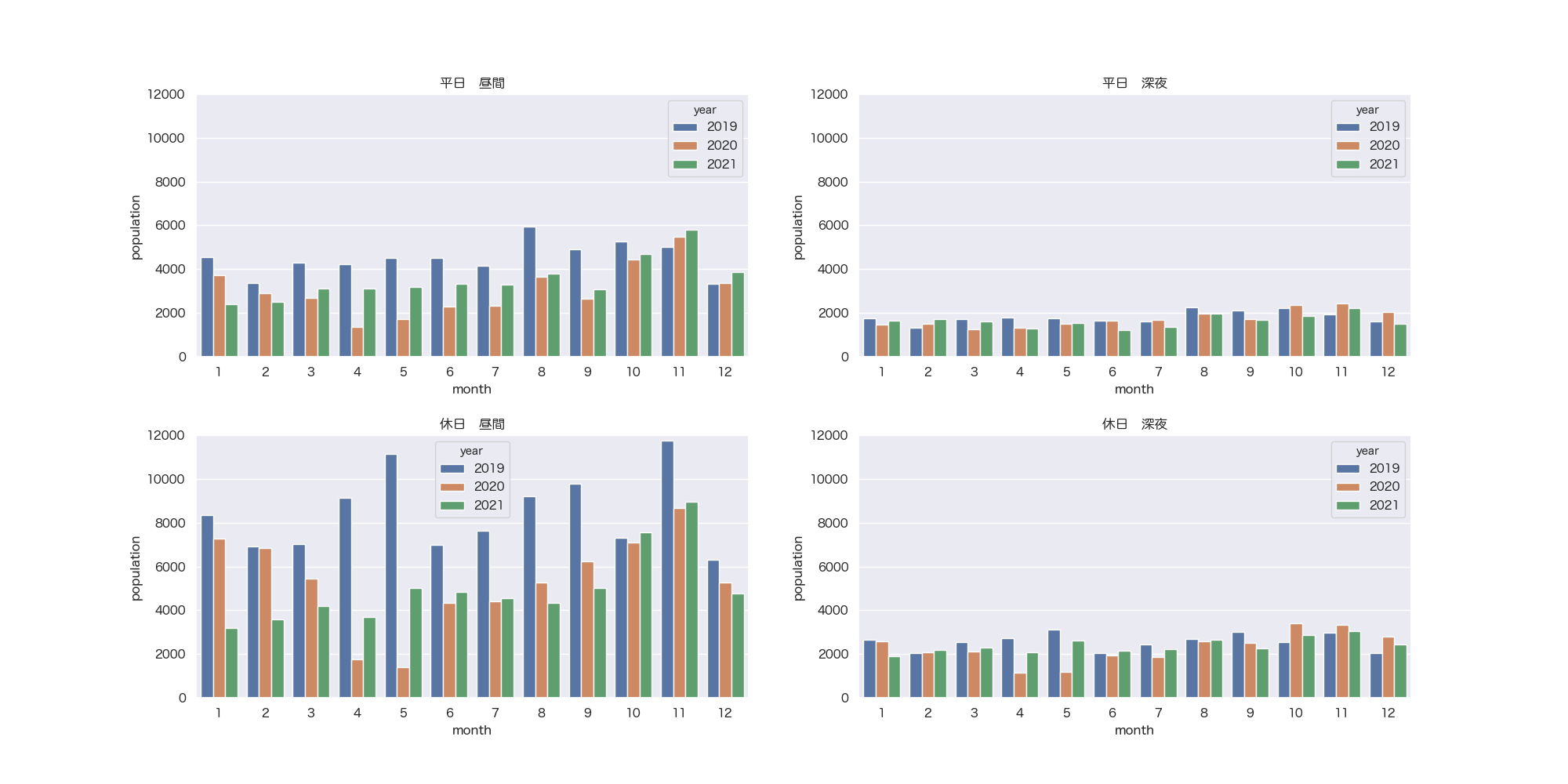
<1kmメッシュ4箇所>
<面積按分後(日光の社寺周辺)>
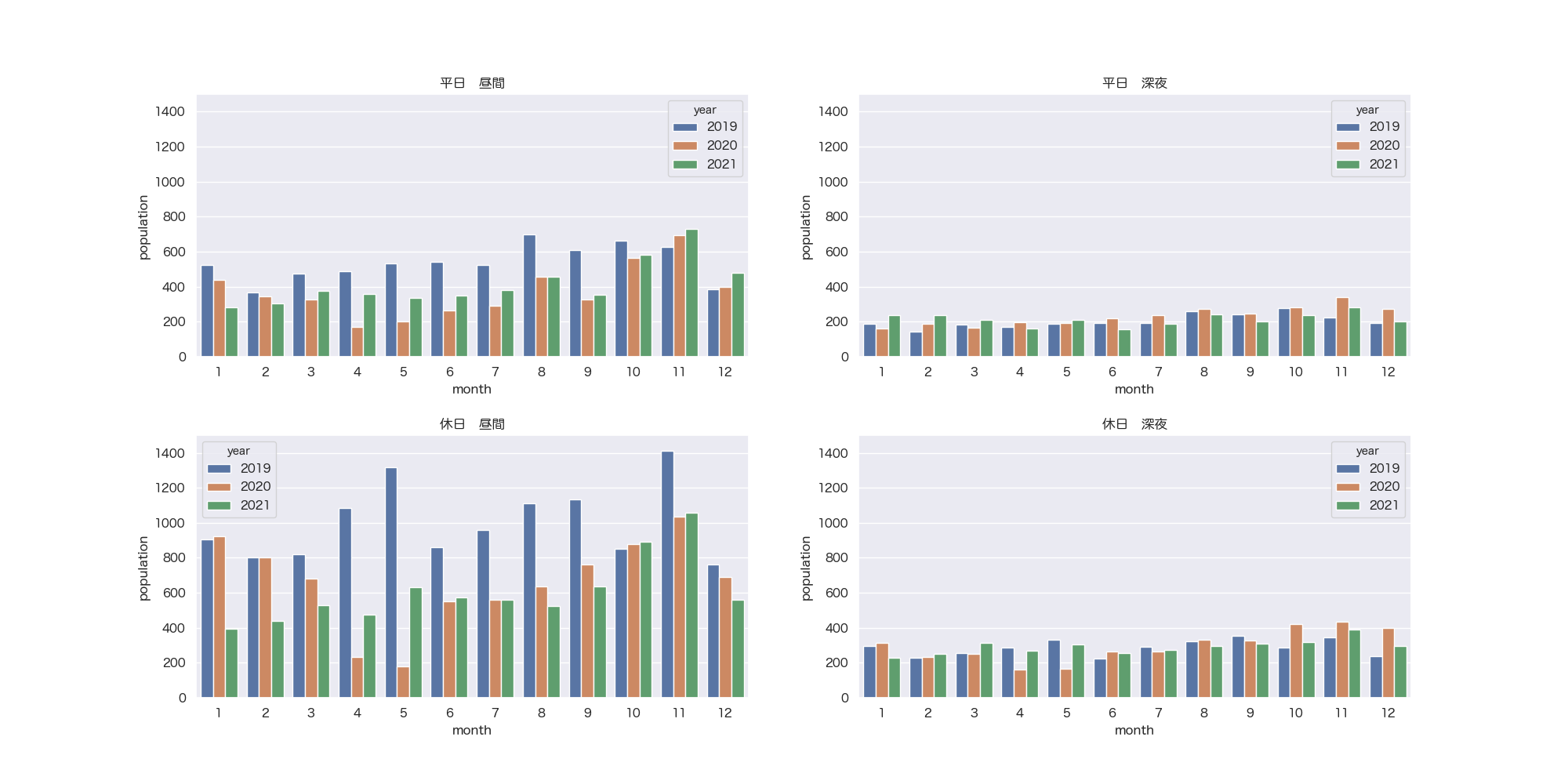
前回同様2020年4月・5月は極端に低い結果となりました。秋は紅葉シーズンだからでしょうか?
やはり素人はExcelでグラフ化したほうが早いような気も。面積按分のほうはこんなもんではないでしょうか。答え合わせができるようなデータがみつからなかったもので。
まとめ
今回は全国の人流オープンデータを面積按分による集計とMatplotlibによるグラフ化をやってみました。今後は別の可視化にもチャレンジしてみようかと思います。