全国の人流オープンデータを触る
以前に疑似人流データ(株式会社ナイトレイ、東京大学 柴崎・関本研究室、マイクロジオデータ研究会、人の流れプロジェクトおよび東京大学空間情報科学研究センター)に関する記事を作成したのですが、閲覧した方からこちらの人流データはどう操作したら良いかというご意見をいただきました。
▼以前の疑似人流データについてです



私も初めてみるデータだったので、最適な回答はできなかったのですが、まずはこのデータを見てみようと思いました。
全国の人流オープンデータとは
国土交通省よりオープンデータとして公開されている人流データです。疑似人流データとは違い、ポイントデータではなく、1kmメッシュデータになります。(市町村別の滞在人口データもありますが、今回は扱いません。)
データはG空間情報センターでダウンロードできます。(ユーザー登録が必要です。無料です。)
概要を以下に簡単ですがまとめておきます。
- 提供エリアは全国
- 集計期間:2019年1月~2021年12月の各月
- 集計単位(平休日):全日/平日/休日
- 集計単位(時間帯):終日/昼(=11時台~14時台の平均)/夜(=1時台~4時台の平均)
- データ形式はCSV
- 1kmメッシュにセットされている人口は、1ヶ月における1日あたりの平均値
- データの提供元はAgoop社
※データ仕様や使用例など、G空間情報センターのダウンロートページに沢山あるので参考にしてみてください。

ファイルの展開が面倒
G空間情報センターでは都道府県別にファイル(zip形式)をダウンロードできるのですが、その解凍後の取り扱いがすこし面倒です。
解凍すると都道府県コードのフォルダに3つ(2019年、2020年、2021年)のフォルダがあります。年別フォルダの中には月別のフォルダがあります。その月別フォルダの中にある個別のCSVがzip形式になっています。
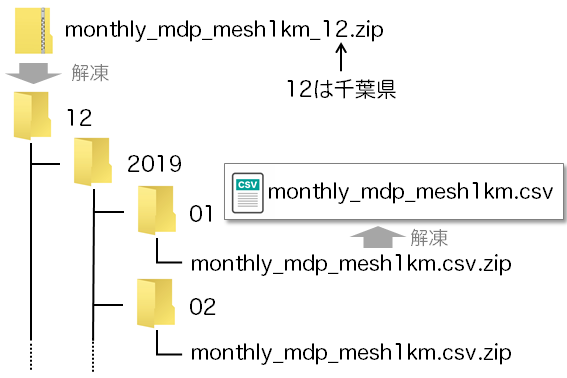
必要となる年月がわかっていればいいのですが、すべて手作業で展開するのは大変です。QGISなどで図化するのであれば、結合作業も必要となるので更に大変。ここはPythonで解決です。(コードは後で)
▼サービス化しました。興味のある方はどうぞ。
全国の人流データ(国土交通省)をダウンロードします 面倒な人流データを直ぐに操作できるCSVファイルに試しに某テーマパーク周辺のデータを集計
試してみてあまり変化がないデータをみても仕方がないので、今回はコロナ禍であからさまに人流の変化がありそうな某テーマパーク周辺のデータを集計してみようと思います。
千葉県浦安市と東京都江戸川区付近の以下のメッシュの人流データを集計します。(面積按分とかはせず、単純に以下のメッシュのみとしました。)
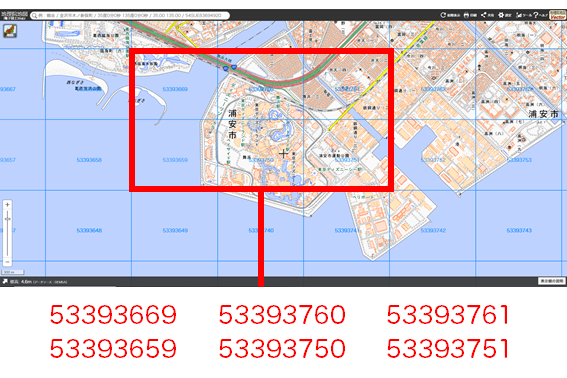
G空間情報センターから東京都と千葉県のデータをダウンロードし、Pythonで展開、集計を一気に行います。
import glob
import zipfile
import pandas as pd
# ファイルの選択(inputフォルダにデータを置いておく)
files = glob.glob('input/monthly_mdp_mesh1km_*.zip')
# 対象メッシュのリスト
mesh_list = [53393659, 53393750, 53393751, 53393669, 53393760, 53393761]
# 読み込みと結合
pieces = []
for file in files:
with zipfile.ZipFile(file)as f:
pref = f.namelist()[0]
for y in range(2019, 2022):
for m in range(1, 13):
with f.open('{}{}/{}/monthly_mdp_mesh1km.csv.zip'.format(pref, str(y), str(m).zfill(2))) as ff:
with zipfile.ZipFile(ff).open('monthly_mdp_mesh1km.csv') as fff:
frame = pd.read_csv(fff)
frame = frame[frame['mesh1kmid'].isin(mesh_list)]
pieces.append(frame)
data = pd.concat(pieces, ignore_index=None)
# 集計
total = data.groupby(['year', 'month', 'dayflag', 'timezone']).sum().reset_index()
total = total.drop(['mesh1kmid', 'prefcode', 'citycode'], axis=1)
# CSVファイルを保存
total.to_csv('output/集計.csv', encoding='shift-jis', index=None)
Matplotlibでグラフ化までやってもいいのですが、ちょっと苦手なので、出力したCSVファイルをExcelのピボットテーブルを利用してグラフ化しました。

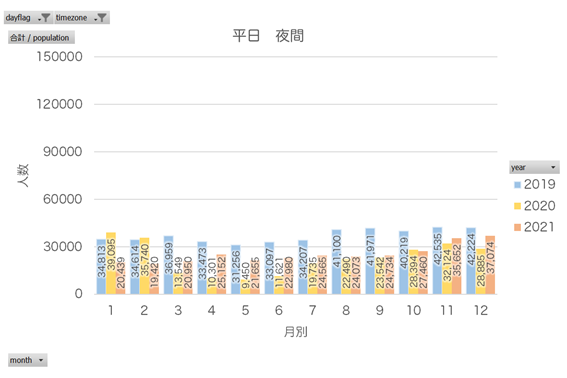
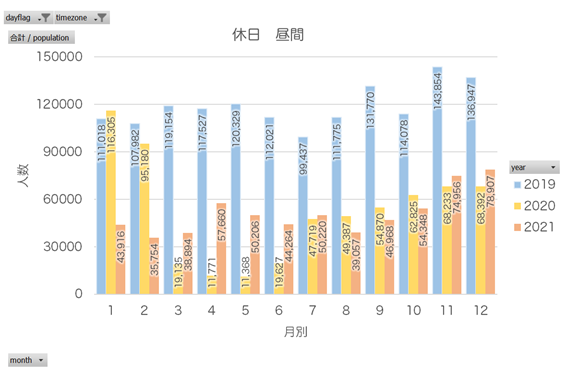
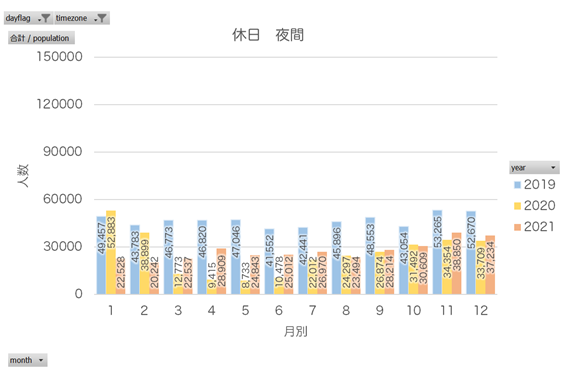
ものすごくわかりやすい結果に。そりゃそうですよね…。休日になると、毎日10万人を超える人が集まる場所というのもすごいです。
QGISでも可視化
休日昼間で最も多かった2019年11月の休日と最も少なかった2020年5月の休日を可視化してみました。結合方法は省略しますが、Pythonで処理しました。
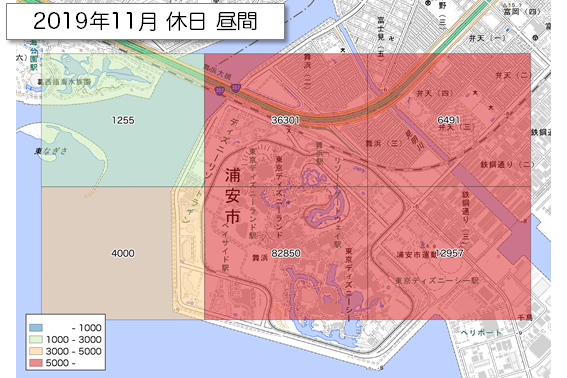
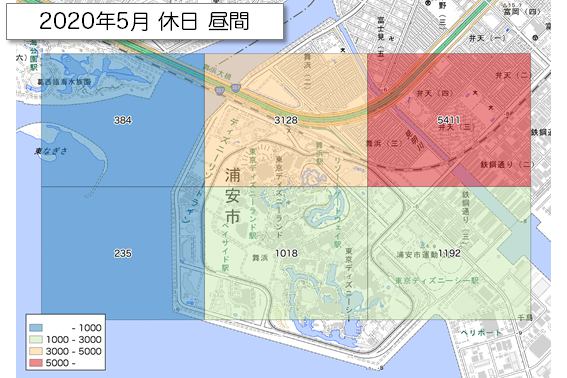
出典「全国の人流オープンデータ」(国土交通省)(https://www.geospatial.jp/ckan/dataset/mlit-1km-fromto)および「地理院タイル」(国土地理院)(https://maps.gsi.go.jp/development/ichiran.html)を加工して作成
中央下のメッシュは一目瞭然。5月はたしか休園していたと思います。1kmメッシュだと少し広いかも知れません。
まとめ
今回は国土交通省の「全国の人流オープンデータ」に触れてみました。メーカーで販売している有料のポイントデータより精度は劣るかもしれませんが、無料でここまでできれば上等です。わがままを言えば500mメッシュも提供してくれないかなあと。
また、G空間情報センターには他にもおもしろそうなデータや、役に立ちそうなデータが沢山ありました。別の機会にチャレンジしてみようかと思います。
▼今回の続編です。Matplotlibでグラフを作成しました
