登記所備付地図データを使ってみる
2023年1月に法務省登記所備付地図データがG空間情報センターより公開されました。当初はXMLファイルのみで何らかのツールで変換しないとGISデータとしては閲覧・加工できなかったものの、最近ではGeoJsonファイルによる公開も始まり障壁は下がってきました。今回はこのデータを触ってみます。
なぜ触ってみる?(もう遅いけど)
登記所備付地図データを最初に知ったのはyahooニュースだったと思います。この地図自体は以前にPDFで入手したことがあったのですが、あれが電子データになったら確かに面白そうと期待していました。
さて、2023年1月に公開されると大盛り上がり?になっていました。
まず、G空間情報センター自体にアクセスが集中し繋がりにくくなっていること。そして、データ自体の使い方がわからないという問題。XMLファイル?これをどうしたら地図が見られるの?といった質問が掲示板に多く書き込まれていました。
私も最初に公開されたコンバーターを使ってみようかとダウンロードはしてみたものの、さっぱり導入方法がわからずそのままにしていました。
ですが、XMLファイル自体は以前にさわってみたことがあったので、Pythonでやればどうにかできるだろうと思いチャレンジしてみました。
▽以前PLATEAUのデータをつかってみました

現在ではG空間情報センターからGeoJsonファイルが公開(2023年4月)されたのでQGISでも直ぐに開くことが出来ます。また、数々の有志の方により変換ソフトやツールが公開されるようになり、当初の問題は解決したと思って良いでしょう。
もうひとつ知っておくべきこと
そもそもデータの内部を見てみると「任意座標」と「公共座標」のものがあり(専門的な内容は検索してみてください。)、容易に地図が閲覧できる物は「公共座標」です。先述のGeoJsonファイルで公開されているものは「公共座標」の箇所のみです。
いくつかの自治体のデータを見てみましたが、ほとんどが「任意座標」で、自治体によっては中心の駅前くらいしか公共座標によるデータがないような箇所もあります。
一応任意座標から公共座標への変換はできるようなのですが、高度の知識が必要となるのであきらめました。まずは公共座標のデータのみGISで確認するのが目標です。
以降2つの方法でやってみました。
その1-Beautiful Soupで解析
pythonでXMLを解析するにはそれ相応のものがあるのですが、スクレイピングで使用するBeautiful Soupで解析してしまおうというかなり無理矢理なやり方です。最初はこれでやったのですが、タグの検索が容易なのでまずは中身を確認してみようという場合は最も楽な方法だと思います。ただし、データ量が多いときは非常に遅くなります。
以下の例は守谷市の守谷駅付近のデータ(基準点)をシェープファイルに変換したものです。ダウンロードしたZIPファイル内に、さらにZIPファイルが入っています。ここでは解析するファイルはわかっている(この例では「08224-0527-75.zip」が守谷駅付近ということを先に調べてある)前提で進めます。
import zipfile
from bs4 import BeautifulSoup
from shapely.geometry import Point
import geopandas as gpd
# 解凍するファイルとCRSの設定(先に調べてあるものとして)
zip_file1 = '08224-0527.zip'
zip_file2 = '08224-0527-75.zip'
crs = 'EPSG:6677'
# zipファイルの解凍
with zipfile.ZipFile(zip_file1) as zf:
with zf.open(zip_file2) as ff:
with zipfile.ZipFile(ff) as zff:
with zff.open(zff.namelist()[0]) as fff:
data = fff.read()
soup = BeautifulSoup(data, "lxml-xml")
# 空間属性<GM_Point>の解析(idと座標の辞書を作成)
point = {}
for member in soup.find_all('GM_Point'):
point[member['id']] = [float(member.find('X').text), float(member.find('Y').text)]
# 主題属性<基準点>の解析
pieces = []
for member in soup.find_all('基準点'):
r = {}
# 属性部分
r['名称'] = member.find('名称').text
r['基準点種別'] = member.find('基準点種別').text
r['埋標区分'] = member.find('埋標区分').text
# ジオメトリの作成
key = member.find('形状')['idref']
r['geometry'] = Point((point[key][1], point[key][0])) # GISではxyが逆になる
pieces.append(r)
# GeoDataFrame作成
gdf = gpd.GeoDataFrame(pieces, crs=crs)
# 保存
gdf.to_file('sample1.shp', encoding='cp932')
その2-lxmlで解析
もう一つは正当な?やり方でしょうか。
XMLファイルの「名前空間」というものが面倒です。コードはちょっと汚いですが、Beautiful Soupのときと同じ成果は得られました。
import zipfile
from lxml import etree as ET
import io
from shapely.geometry import Point
import geopandas as gpd
# 解凍するファイルとCRSの設定(先に調べてあるものとして)
zip_file1 = '08224-0527.zip'
zip_file2 = '08224-0527-75.zip'
crs = 'EPSG:6677'
# zipファイルの解凍
with zipfile.ZipFile(zip_file1) as zf:
with zf.open(zip_file2) as ff:
with zipfile.ZipFile(ff) as zff:
with zff.open(zff.namelist()[0]) as fff:
data = fff.read()
tree = ET.parse(io.BytesIO(data))
root = tree.getroot()
# 空間属性<GM_Point>の解析(idと座標の辞書を作成)
point = {}
for child in root.findall('.//{http://www.moj.go.jp/MINJI/tizuzumen}GM_Point'):
id = child.attrib['id']
x = float(child.find('.//{http://www.moj.go.jp/MINJI/tizuzumen}X').text)
y = float(child.find('.//{http://www.moj.go.jp/MINJI/tizuzumen}Y').text)
point[id] = [x, y]
# 主題属性<基準点>の解析
pieces = []
for child in root.findall('.//{http://www.moj.go.jp/MINJI/tizuxml}基準点'):
r = {}
# データ取得部分
for c in child:
if '形状' in c.tag: # 形状の要素のみidrefを取得する必要がある
v = c.attrib['idref']
# ジオメトリ作成
r['geometry'] = Point((point[v][1], point[v][0])) # GISではxyが逆になる
else:
v = c.text
k = c.tag.replace('{http://www.moj.go.jp/MINJI/tizuxml}','')
r.setdefault(k, v)
pieces.append(r)
# GeoDataFrame作成
gdf = gpd.GeoDataFrame(pieces, crs=crs)
# 保存
gdf.to_file('sample2.shp', encoding='cp932')
両方とも同じポイントデータが作成されています。
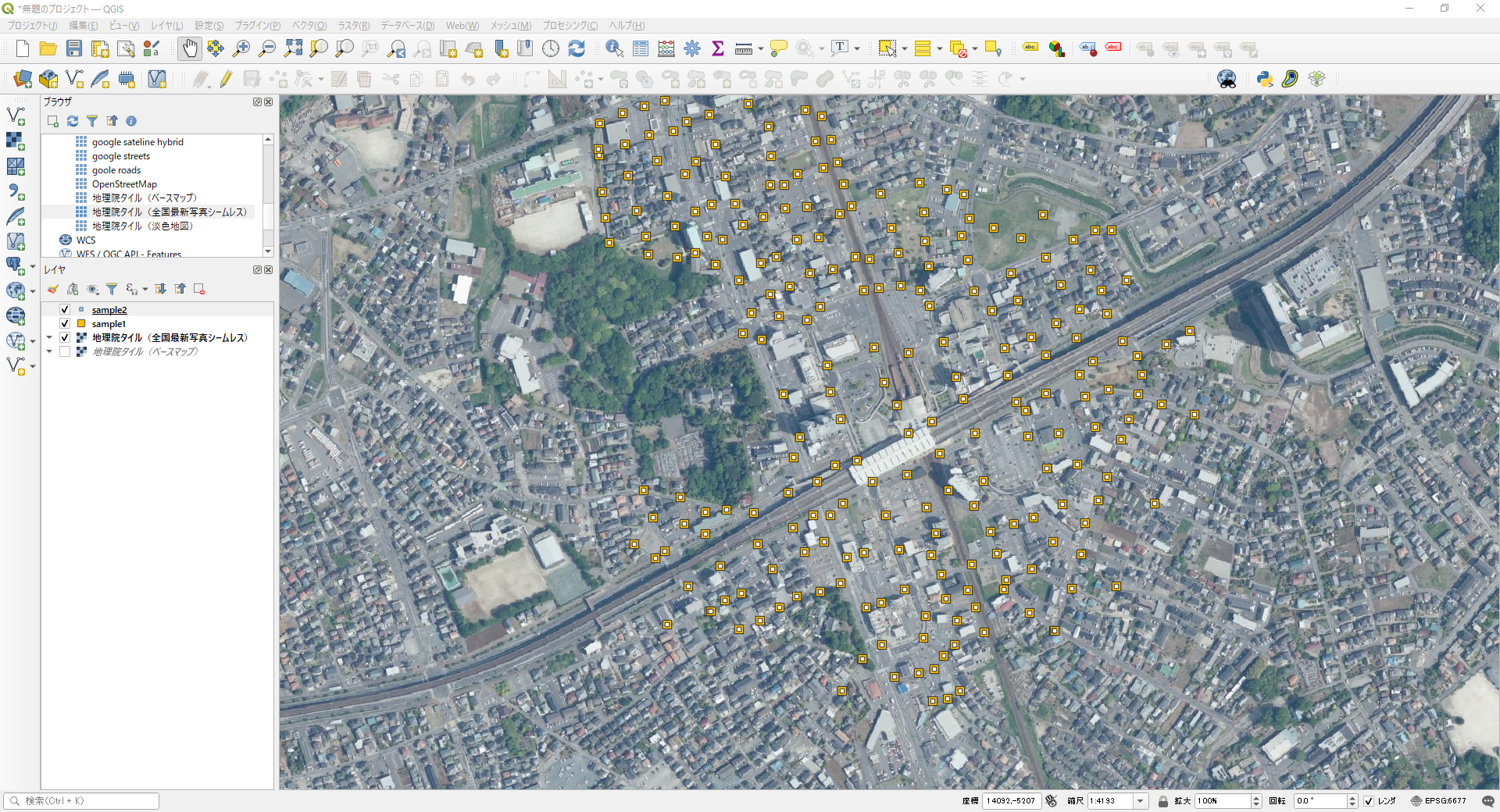
出典「登記所備付地図データ 守谷市」(法務省)(https://front.geospatial.jp)および「地理院タイル」(国土地理院)(https://maps.gsi.go.jp/development/ichiran.html)を加工して作成
まとめ
今回は登記所備付地図データについて触れてみました。
ちなみにKMLファイルで出力すればGoogleマップで閲覧できます。こちらはサービス化してみましたので興味がある方はどうぞ。
登記所備付地図データをKMLファイルに変換します 登記所備付地図データがGoogleマップで閲覧できる