成田空港へ 京成vsJR
最近知ったのですが、大都市交通センサスのデータがe-statで公開されています。しかも、最新版は新型コロナウイルスの影響で、調査票による調査ではなくICカードの集計データが公表されています。早速これをつかって、タイトルのとおり、成田空港へのアクセス鉄道である京成とJRの割合を見てみようと思いました。
大都市交通センサスとは(簡単に)
簡単に言えば都市圏(首都圏、中京圏、近畿圏)における、鉄道・バス等の利用実態にかかわる統計資料です。随分昔に路線バスでこの調査票を受け取った思い出があります。
最新の第13回調査(2021年)は、本来2020年に実施すべきものを新型コロナウイルスの影響で1年延期し、さらには調査票を用いない方式になったそうです。そのため、定期外の部分ではICカードの集計データが公表されました。
詳しくは以下を参考
国土交通省(調査の概要)
https://www.mlit.go.jp/sogoseisaku/transport/sosei_transport_tk_000007.html
e-stat(データのダウンロード)
今回のデータは特定の駅から特定の駅までのデータが見られるので首都圏のどんな駅から成田空港まで来ているのか、そして京成とJRのどちらで降車しているのかがわかるようになります。
データはクセありです
ICカードのデータは「一件明細調査」というものになります。そこで0次OD~3次ODというものに分かれています。今回は出発地から到着地までの1トリップになっている2次ODデータを使用しました。
そして、この2次ODデータだけでダウンロードするファイル(めちゃくちゃ思いCSVファイル)が42個あります。接続時間の閾値(乗り換え時間を何分まで許容するか)と調査日(2日間のうち1日目と2日目)が分かれています。今回は閾値30分・1日目を対象としました。
ダウンロードしたCSVはExcelで開けない膨大なものです。PythonのPandasで処理しようとしましたが、これでも重いので、まずは首都圏のデータだけを抽出して分析することにしました。(結局Pandasとあまり変わらなかったかも)
さらに一癖、それぞれの区分でCSVだけカラム名があり、続きのものにはない(どうせなら毎回カラム名をつけてくれ・・・)という形式です。
import glob
import csv
import pandas as pd
# inフォルダにあるCSVファイル7個のリスト
files = glob.glob('in\2ji_30_1*.csv')
# 首都圏のデータだけ読み込む
data = []
for file in files:
with open(file, encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
if row[0] == '1.首都圏':
data.append(row)
# カラム名の設定(初期値だと使いにくいので)
columns = ['area', 'card',
'in_area','in_company', 'in_line', 'in_station', 'in_pref', 'in_city', 'in_time',
'out_area', 'out_company', 'out_line', 'out_station', 'out_pref', 'out_city',
'time', 'via', 'people']
# データフレームを作成
df = pd.DataFrame(data, columns=columns)
# df.head() # どんな感じか見てみる
# CSVで保存(文字エンコードはExcelでも見たいのでこれで)
df.to_csv('2ji-30-tokyo1.csv', encoding='utf-8-sig', index=None)これで首都圏だけのCSVを保存しておけば、ほかのことにも使えるかと。
それで成田空港は・・・
ここまで来てやっと成田空港のデータを抽出できる段階にきました。Pandsで集計してみます。
import pandas as pd
# 読み込み、成田空港と空港第2ビル着のみ抽出(幸い京成もJRも同じ駅名でOK)
df = pd.read_csv('2ji-30-tokyo1.csv')
df = df[(df['out_station']=='空港第2ビル') | (df['out_station']=='成田空港')]
df.head()
# ピボットテーブルで集計
pivot = pd.pivot_table(df, index=['in_company', 'in_line', 'in_station'], columns='out_company',
values='people', aggfunc='sum', fill_value=0).reset_index()
# 割合の計算
pivot['京成割合'] = pivot['京成電鉄'] / (pivot['京成電鉄'] + pivot['東日本旅客鉄道']) * 100
pivot['JR割合'] = 100 - pivot['京成割合']
# pivot.head()
# CSVで保存
pivot.to_csv('ピボット集計.csv', encoding='utf-8-sig')ここまでわかりやすくすれば、あとはExcelで自由に編集すればいいかと思います。
ひとまず、成田空港駅と空港第2ビル駅の合計の上位がこんな感じです。
| 会社 | 発駅 | 京成利用 (人) | JR利用 (人) | 京成割合 (%) | JR割合 (%) |
| 京成 | 京成成田 | 846 | 0 | 100.0 | 0.0 |
| JR | 成田 | 0 | 487 | 0.0 | 100.0 |
| 京成 | 公津の杜 | 340 | 4 | 98.8 | 1.2 |
| 京急 | 横須賀中央 | 121 | 3 | 97.6 | 2.4 |
| 京成 | 勝田台 | 95 | 1 | 99.0 | 1.0 |
| JR | 千葉 | 3 | 93 | 3.1 | 96.9 |
| 京成 | 日暮里 | 87 | 0 | 100.0 | 0.0 |
| 京成 | 八千代台 | 77 | 1 | 98.7 | 1.3 |
| 京成 | 京成船橋 | 70 | 0 | 100.0 | 0.0 |
| 北総 | 千葉ニュータウン中央 | 67 | 1 | 98.5 | 1.5 |
どうしても周辺駅は定期券で無くても通勤している人もいるので、上位に集中しているのではないかと思います。千葉のように総武本線や千葉都市モノレーJRの割合が大きかったです。意外だったのは横須賀中央。米軍関係者の出国者なのでしょうか。
また、注意点としてICカードのデータなのできっぷの利用者ではないことです。訪日外国人はジャパンレールパス(訪日外国人向けのJR線乗り放題のきっぷ)も使っている方も多いそうなので、定期外の傾向としては、もう少しJR線も割合は多いのかもしれません。
foliumで可視化
表をみても「ふむふむ」で終わってしまったので、地図で可視化してみました。
赤は京成優位の駅、緑はJR優位の駅です。駅の座標は以前にも利用した「駅データ.jp」のものを利用しました。(接続駅で重なってしまう駅は加工して座標をずらしています。)
▼下の画像をクリックすると大きな地図で閲覧できます。
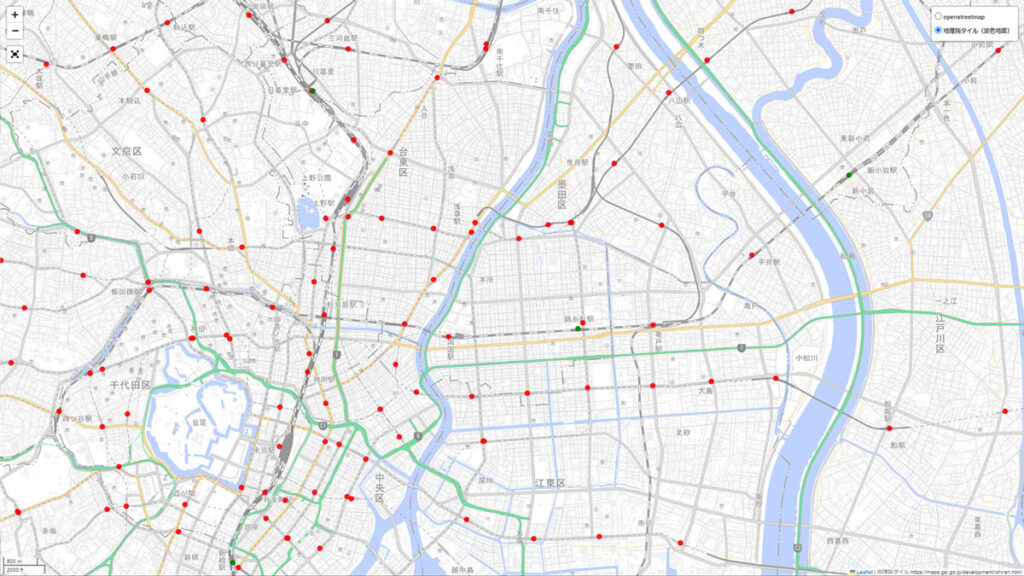
出典:「第13回大都市交通センサス」(国土交通省)(https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00600020&tstat=000001103355&cycle=0&tclass1=000001203341&tclass2=000001203350&tclass3=000001203821&tclass4val=0)および「地理院タイル」(国土地理院)(https://maps.gsi.go.jp/development/ichiran.html)を加工して作成
▽foliumの基礎的な使い方が調べられます。
まとめ
今回はe-statで公開されている大都市交通センサスデータを集計、可視化してみました。成田空港よりも舞浜駅とかでやってみたら新たな発見があるかも知れません。