ランキングの変動を可視化
外国の書籍になりますが、『Visual Complexity Mapping Patterns of Information』という本をご存じでしょうか。(日本語に翻訳されているものが発売されています。)主にネットワークの可視化(=ビジュアライゼーション)について紹介されていて、可視化の手段よりも芸術としての側面が強いかも知れません。
この中から、ニュース媒体の利用の比較分析の図を参考になにかできないかと考えました。
都道府県別人口ランキングの推移を可視化
簡単に入手できる国勢調査のデータを利用して人口データの推移を可視化してみようと思います。
DBを選択して加工しやすい形に整形したexcelファイルをダウンロードしておきます。(詳細省略)
早速matplotで可視化します。ベジェ曲線を描くためにこちらを参考にさせてもらいました。
1920年から2020年までの都道府県別人口ランキングの変化を10年間隔でみてみます。(画像ファイルはトリミングしています。)
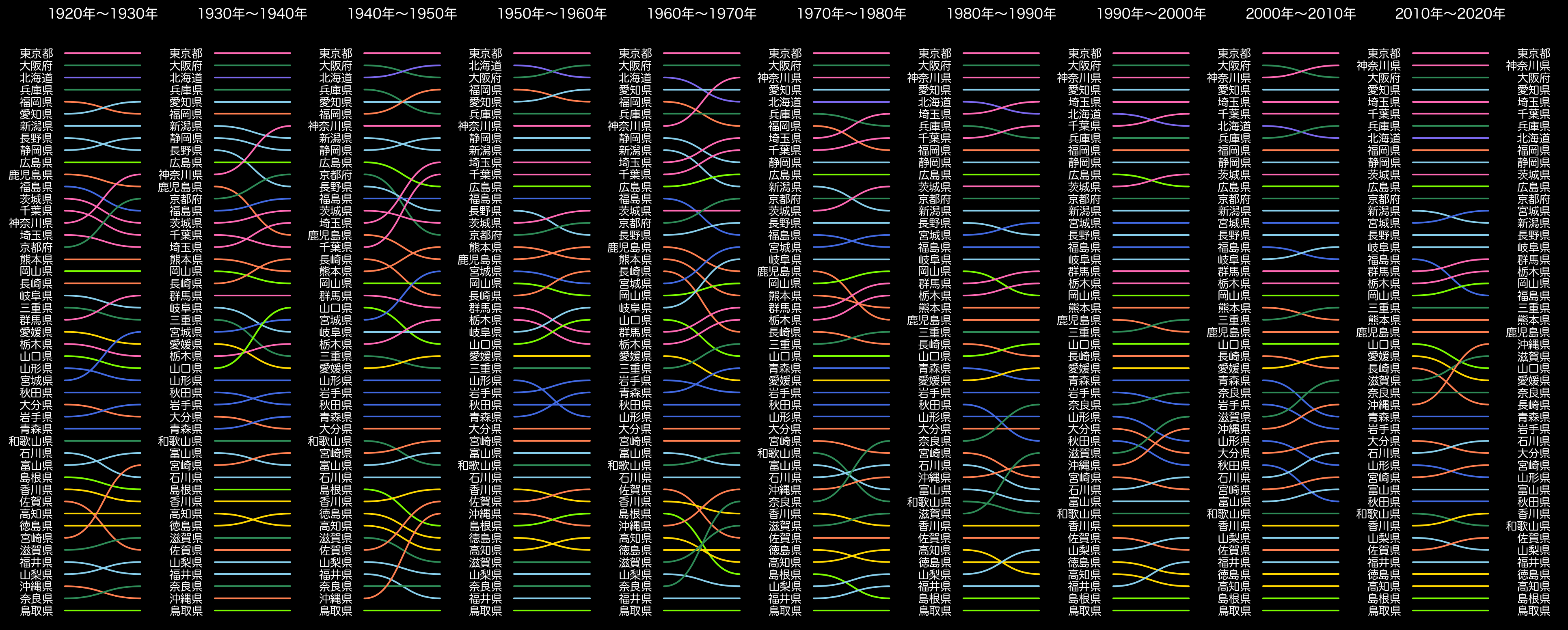
出典:「国勢調査/時系列データ/男女、年齢、配偶関係」(総務省統計局)(https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001011778&stat_infid=000001085925&tclass2val=0)を加工して作成
5年間隔でもやってみます。
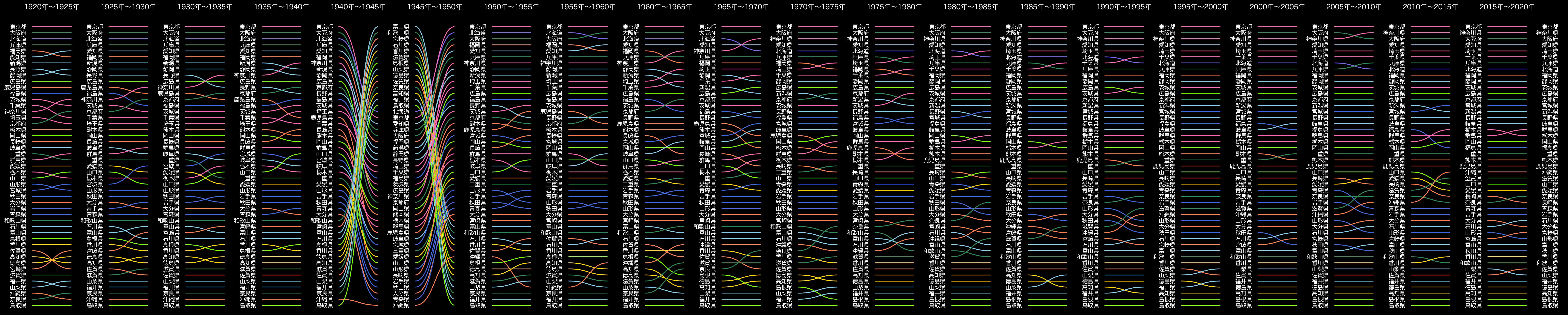
出典:「国勢調査/時系列データ/男女、年齢、配偶関係」(総務省統計局)(https://www.e-stat.go.jp/stat-search/files?page=1&layout=datalist&toukei=00200521&tstat=000001011777&cycle=0&tclass1=000001011778&stat_infid=000001085925&tclass2val=0)を加工して作成
コードは以下のとおり。素人だと無駄が多すぎる…。分岐のところがもっとうまくならないものか。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# ベジェ曲線を描く関数
def bezier_curve4(r1, r2):
# 点の座標
q1 = [0, -r1]
q2 = [0.5 , -r1]
q3 = [0.5 , -r2]
q4 = [1, -r2]
Q = [q1, q2, q3, q4]
px = []
py = []
t = np.arange(0, 1, 0.01)
for i in range(len(t)):
P = np.dot((1 - t[i]) ** 3, Q[0]) + np.dot(3 * (1 - t[i]) ** 2 * t[i], Q[1]) + np.dot(3 * (1 - t[i]) * t[i] ** 2, Q[2]) + np.dot(t[i] ** 3, Q[3])
px.append(P[0])
py.append(P[1])
return px, py, Q
# 可視化する年を設定
year_from = 1920 # 開始
year_to = 2020 # 終了
distance = 10 # 間隔
# ラインカラーの設定
color = {'北海道': 'mediumslateblue',
'青森県': 'royalblue', '岩手県': 'royalblue','宮城県': 'royalblue', '秋田県': 'royalblue', '山形県': 'royalblue', '福島県': 'royalblue',
'茨城県': 'hotpink', '栃木県': 'hotpink', '群馬県': 'hotpink', '埼玉県': 'hotpink', '千葉県': 'hotpink', '東京都': 'hotpink', '神奈川県': 'hotpink',
'新潟県': 'skyblue', '富山県': 'skyblue', '石川県': 'skyblue', '福井県': 'skyblue', '山梨県': 'skyblue', '長野県': 'skyblue', '岐阜県': 'skyblue', '静岡県': 'skyblue', '愛知県': 'skyblue',
'三重県': 'seagreen', '滋賀県': 'seagreen', '京都府': 'seagreen', '大阪府': 'seagreen', '兵庫県': 'seagreen', '奈良県': 'seagreen', '和歌山県': 'seagreen',
'鳥取県': 'lawngreen', '島根県': 'lawngreen', '岡山県': 'lawngreen', '広島県': 'lawngreen', '山口県': 'lawngreen',
'徳島県': 'gold', '香川県': 'gold', '愛媛県': 'gold', '高知県': 'gold',
'福岡県': 'coral', '佐賀県': 'coral', '長崎県': 'coral', '熊本県': 'coral', '大分県': 'coral', '宮崎県': 'coral', '鹿児島県': 'coral', '沖縄県': 'coral'}
columns = [str(y) + '年' for y in range(year_from, year_to + 1, distance)]
# データ読み込み
df = pd.read_csv('人口推移.csv', index_col=[0], na_values=np.nan, encoding='shift-jis')
# ランキングを作成
ranking = df.rank(ascending=False)
# プロットの設定
n = len(columns) # サブプロットの数
fig, ax = plt.subplots(1, n + 1, figsize=(2.5*n, 10), dpi=200, facecolor='k', subplot_kw=dict(facecolor='k'))
for i in range(n):
# データの抽出
if i == n - 1: # 最後はダミーとして9999年のカラムを作成する
data = ranking[[columns[i]]].sort_values(by=columns[i])
data['9999年'] = data[columns[i]]
flag = 1
else:
data = ranking[[columns[i], columns[i+1]]].sort_values(by=columns[i])
flag = 0
# 主目盛りの設定
ax[i].set_xticks([0 , 1])
ax[i].set_yticks(list(range(-1, -48, -1))) # -1が1位、-2が2位・・・
# スケールの設定
ax[i].set_xticklabels(['', ''])
ax[i].set_yticklabels(data.index, color='w', fontname='Hiragino Maru Gothic ProN')
# プロット
for index, row in data.iterrows():
px, py, Q = bezier_curve4(row[0], row[1])
if flag == 1:
ax[i].plot(px, py, color='k', solid_capstyle='round')
else:
ax[i].plot(px, py, color=color[index], solid_capstyle='round')
# タイトル
ax[i].set_title(columns[i] + '~' + columns[i+1], loc='center', color='w', fontname='Hiragino Maru Gothic ProN')
# レイアウト設定
fig.subplots_adjust(wspace=0.8)
# グラフを表示する。
plt.show()
まとめ
今回は人口推移について、ビジュアルにも考慮しつつ可視化してみました。Pythonを利用することでExcelにはないような可視化ができるようになったのは一歩前進した?